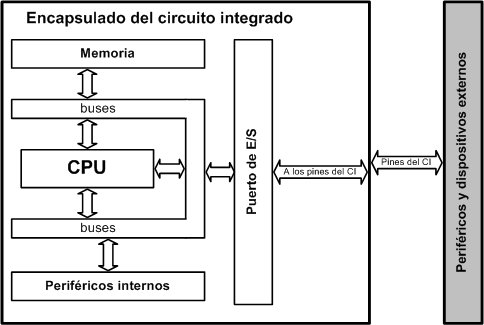
La administración de sistemas distribuidos incluye
las actividades como: manejo de la versión y distribución del software,
monitoreo de la utilización de los recursos y el mantenimiento del sistema de
seguridad, entre otros.
Los administradores de sistemas distribuidos se
ocupan de monitorear continuamente al sistema y se deben de asegurar de su
disponibilidad. Para una buena administración, se debe de poder identificar las
áreas que están teniendo problemas así como de la rápida recuperación de fallas
que se puedan presentar. La información que se obtiene mediante el monitoreo
sirve a los administradores para anticipar situaciones criticas. La prevención
de estas situaciones ayuda a que los problemas no crezcan para que no afecten a
los usuarios del sistema.
5.2 Instalación
de clusters
En este caso se instalara el sistema operativo
distribuido Linux. Preparación Primero vamos a probar el sistema antes de
instalarlo. Para ello, debemos tener un CD de Ubuntu. Podemos hacerlo de varias
maneras:
1. Descargarlo desde la página web oficial.
2. Pedirlo a través de shipit (tarda de 4 a 6 semanas en llegar)
3. Obtener una copia a través de un conocido.
Independientemente del método que usé, el disco que obtendrá será el mismo. Una
vez que tengas el CD, debe configurar la BIOS para que nos lea el CD antes de
arrancar el disco duro.
Puedes comprobar si lo tienes correctamente
configurado introduciendo el CD de Ubuntu y reiniciando el sistema. Si carga el
CD lo tienes bien, si no lo carga, debes hacer lo siguiente. Nada más encender
el ordenador, aparece una pantalla negra con letras. Debe ser algo parecido a
esto: ¿Veis que dice “Press DEL to enter SETUP”? Eso significa que pulsando la
tecla Suprimir entraremos a la configuración. Advierto que la tecla varía de
unas BIOS a otras. Aquí es Suprimir pero podría ser F2 o F12.
Todo es fijarse y pulsarla. Una vez hecho esto,
aparecerá una pantalla típicamente azul. Dentro de ella, debemos buscar algo
así como Boot Order, y poner al lector de CD el primero y al disco duro en
segundo lugar. Si lo hemos hecho bien, deberá quedarse como en la imagen de
abajo. Una vez ajustado este parámetro, buscamos la tecla para salir de la BIOS
guardando los cambios (“Save and Exit setup” suele ser la frase asociada a tal
tecla). Una vez guardemos los cambios el sistema se reiniciará y debería cargar
el CD del lector.
Si sigues teniendo problemas contacta con nosotros
o pide ayuda en un foro especializado. Una vez consiga cargar el CD, veremos el
siguiente menú: Debemos seleccionar la opción “Probar Ubuntu sin alterar el
equipo”, puesto que es lo que queremos. Tardará unos 5 minutos en arrancar. Una
vez arranque, tendremos listo el sistema para un primer uso. El primer contacto
Al iniciar, tendremos una pantalla parecida a esta.
Vemos 3 menús (Aplicaciones, Lugares y Sistema).
Desde Aplicaciones podremos acceder a los programas instalados en el sistema.
En Lugares podremos encontrar accesos a los directorios relevantes del sistema.
Por último, en el menú sistema podremos configurar aspectos de nuestro sistema
(salvapantallas, temas, pantalla de entrada, bluetooth,...)
Dado que estamos iniciando desde el CD, podemos
tocar todo lo que queramos sin que esto repercuta en nuestro sistema. Así que
lo mejor es comprobar que todo el hardware o casi todo funiona. Por lo demás,
simplemente podemos ver las aplicaciones que vienen con el sistema y
familiarizarnos un poco con él. Si queremos instalar hacemos doble clic en el
icono que hay en el escritorio.
Si no queremos instalarlo, pulsamos en el botón que
hay en la parte superior derecha, donde dice “Live Session User”, desde ahí
podremos apagar el sistema. Instalando el sistema Para instalar el sistema,
hacemos doble clic en el icono del escritorio que dice instalar. Nos aparecerá
un asistente que nos guiará en toda la instalación. Aquí nos saltamos los
primeros pasos porque son muy sencillos (Idioma, distribución del teclado y
zona horaria). Así pues, llegamos al paso del particionado.
Lo más fácil es usar una de las opciones prefijadas
que nos da el instalador, ya que nos evita este pasó. De todas formas, si lo
que queremos es algo personalizado, debemos especificar las particiones
manualmente. Debemos recordar que para funcionar correctamente, Ubuntu necesita
dos particiones: una ext3 (o ext4) y una partición SWAP. Si elegimos un
particionado personalizado crearlas es muy sencillo. Debemos seleccionar un
espacio en blanco y crear una partición con formato ext3/ext4 y el tamaño que
nosotros elijamos. Además, el punto de montaje de esta partición debe ser /
puesto que será nuestra partición raíz. Debe quedar algo parecido a esto: Para
la partición SWAP, debemos darle un tamaño aproximado de 1 GB.
Las particiones swap no tienen punto de montaje así
que es mucho más sencillo crearlas. Una vez creada debe ser parecido a esto:
Recordad que los tamaños de las particiones (tanto la raíz como SWAP se
escriben MB. Para pasar a GB debéis dividir por 1024). Una vez tengamos el
particionado completo pasamos a rellenar los datos de usuario.
Si tenemos una partición con una versión de
Windows, el instalador nos ofrecerá la opción de utilizar los datos de esa
cuenta para Ubuntu. Si es lo que quieres, marcas las casillas correspondientes
y listo.
Detallamos un poco como rellenar estos apartados. En el primero debemos poner
nuestro nombre. En el segundo, el nombre para iniciar sesión. Este nombre sólo
puede contener minúsculas. La contraseña es a vuestra elección. El nombre del
equipo es el nombre con el que otros usuarios verán al equipo en la red. Por
último, podremos seleccionar si queremos que este usuario se identifique en el
sistema automáticamente o por el contrario pida la contraseña. Esto último es a
nuestra elección.
Una vez hayamos terminado de configurar todos los
apartados, se nos mostrará un resumen de todos los cambios que el instalador
hará en el sistema. Conviene comprobarlos para ver si está todo correcto. Si lo
está, pulsamos en Instalar y comenzará la instalación del sistema. Suele durar
unos 15-20 minutos. Cuando termine, nos mostrará una pantalla para, o bien
continuar usando el sistema del CD, o bien reiniciar y empezar a usar el nuevo
sistema.
Si seguEs utilizando el CD, recordad que para salir
debEs pulsar en el botón que hay en la parte superior derecha. Al reiniciar,
usaremos el sistema nuevo, con las mismas características que el del CD, pero
trabajando mucho más rápido. Ahora pasaremos a la correcta configuración del
sistema, que es otro aspecto importante a tener en cuenta.
5.3 Estandares
administracion en Sistemas Distribuidos
El establecimiento de estándares
Aquellas normas usuales, los propósitos, los
objetivos, a alcanzar, los datos de carácter histórico las directrices que
guían las actividades, las predicciones sobre el volumen de estas, las metas a
alcanzar y aquellos índices que integran los planes , y todo dato o cifra que
pueda emplearse como medida para cumplirlas, son considerados como estándares.
Estas medidas son indispensables para el control,
ya que indican la manera en que deseas que se ejecute una actividad. En la
práctica, son los objetivos declarados y definidos de la organización y por esa
razón los estándares deben abarcar las funciones básicas y áreas clave de los
resultados logrados.
Para construir los estacares, debe partirse del análisis
de procesos, como las normas de trabajo o de costos y la recopilación de
experiencias anteriores.
Estándares estadísticos o históricos: parten del
análisis de datos de experiencias logradas, que muchas veces son complementadas
con el criterio personal.
Los estándares elaborados técnicamente se
fundamentan en el estudio objetivo y cuantitativo de una situación de trabajo
específica.
Los estándares puedes ser físicos, intangibles, de
costos, de inversión, de recursos o medios de producción, de ingresos o de
resultados, y expresarse cuantitativamente, en unidades numéricas, de uno u
otro tipo(moneda, volumen, capacidad ), o cualitativos, cunado se establecen
subjetivamente y lo que se mide y evalúa se refiere a cierta calidad(impacto en
el mercado, nombre de la empresa, precio en la competencia).
Los estándares pueden representar calidad, mediante
índices o calificaciones convencionales o por medio de coeficientes.
5.4 Computo de alto rendimiento a bajo costo
En la actualidad, es factible disponer de alta capacidad computacional, incluso equivalente a la encontrada en las poderosas y costosas supercomputadoras clásicas, mediante clusters (conglomerados) de computadoras personales (PCs) independientes, de bajo costo, interconectadas con tecnologías de red de alta velocidad, y empleando software de libre distribución. El conglomerado de computadoras puede trabajar de forma coordinada para dar la ilusión de un único sistema. Este artículo presenta las ideas básicas involucradas en el diseño, construcción y operación de clusters, presentando aspectos relacionados tanto al software como al hardware. Se presentan los diferentes tipos de clusters, su arquitectura, algunas consideraciones de diseño, y se mencionan ejemplos concretos del hardware para los nodos individuales y para los elementos de interconexión de alta velocidad, así como ejemplos concretos de los sistemas de software para el desarrollo de aplicaciones y administración de los clusters.
5.5 Super computo basado en clustering
La tecnología de clústeres ha evolucionado en apoyo de actividades que van desde aplicaciones de supercómputo y software de misiones críticas, servidores web y comercio electrónico, hasta bases de datos de alto rendimiento, entre otros usos.
El cómputo con clústeres surge como resultado de la convergencia de varias tendencias actuales que incluyen la disponibilidad de microprocesadores económicos de alto rendimiento y redes de alta velocidad, el desarrollo de herramientas de software para cómputo distribuido de alto rendimiento, así como la creciente necesidad de potencia computacional para aplicaciones que la requieran.
Simplemente, un clúster es un grupo de múltiples ordenadores unidos mediante una red de alta velocidad, de tal forma que el conjunto es visto como un único ordenador, más potente que los comunes de escritorio.
Los clústeres son usualmente empleados para mejorar el rendimiento y/o la disponibilidad por encima de la que es provista por un solo computador típicamente siendo más económico que computadores individuales de rapidez y disponibilidad comparables.
5.6 Tendencias de
Investigacion
Hoy en día, y gracias a la tecnología, "el
termino centralizado" está desapareciendo, con la llegada de la redes de
ordenadores podemos compartir recursos sin preocuparnos de la ubicación
geográfica de la otra persona, podemos manejar ordenadores como si estuviésemos
trabajando físicamente en ellos, además de transmitir información o escribir
cartas que llegan al receptor en lapsos de tiempo mínimos.
Por ellos existen dos arquitecturas que resuelven
dichos problemas Arquitectura SMP (Uma) Arquitectura DSM (Numa.) Arquitectura
SMP (Uma) Los multiprocesadores simétricos (Symmetric Multiprocessor): son
ordenadores con arquitectura de memoria compartida que presentan en la memoria
principal un acceso simétrico desde cualquier procesador, es decir, el retardo
en el acceso a cualquier posición de memoria es el mismo con independencia del
procesador desde el que se realice la operación o tarea, dicha arquitectura es
denominada como "Acceso Uniforma a Memoria" (UMA) y se lleva a cabo
con una memoria compartida pero centralizada. Estos multiprocesadores dominan
el volumen como el capital invertido.
Arquitectura
DSM (Numa).
Esta
arquitectura de memoria que se genera en retardo de acceso dependiente tanto la
posición de memoria como el procesador se denomina Acceso No Uniforme a Memoria
(NUMA), hace su aparición cuando la memoria compartida está distribuida entre
los nodos. De esta manera, se mejora el retardo medio de acceso a memoria, ya
que en cada ordenador los accesos a posiciones de su memoria local presentan un
retardo sensiblemente inferior al caso en que es accedido a posiciones de
memoria en otros ordenadores. Esta clase de ordenadores con arquitectura NUMA
presentas escalabilidad. Propone un espacio de direcciones de memoria virtual
que integre la memoria de todas las computadoras del sistema, y su uso mediante
paginación.
Las
páginas quedan restringidas a estar necesariamente en un único ordenador.
Cuando un programa intenta acceder a una posición virtual de memoria, se
comprueba si esa página se encuentra de forma local. Si no se encuentra, se
provoca un fallo de página, y el sistema operativo solicita la página al resto
de computadoras. El sistema funciona de forma análoga al sistema de memoria
virtual tradicional, pero en este caso los fallos de página se propagan al
resto de ordenadores, hasta que la petición llega al ordenador que tiene la
página virtual solicitada en su memoria local. A primera vista este sistema
parece más eficiente que el acceso a la memoria virtual en disco, pero en la
realidad ha mostrado ser un sistema demasiado lento en ciertas aplicaciones, ya
que provoca un tráfico de páginas excesivo.
Sistema
realmente distribuido.- El objetivo es crear la ilusión en la mente de los
usuarios de que toda la red es un solo sistema de tiempo compartido.
Características: Debe existir un Mecanismo de comunicación global entre los
procesos (cualquiera puede hablar con cualquiera). No tiene que haber distintos
mecanismos en distintas máquinas o distintos mecanismos para la comunicación
local o la comunicación remota. Debe existir un esquema global de protección.
La administración de procesos debe ser la misma en todas partes (crear,
destruir, iniciar, detener). Debe existir un sistema global de archivos y debe
tener la misma apariencia en todas partes.
El
rasgo clave es que existe una sola cola para una lista en el sistema, de los
procesos que no se encuentran bloqueados y que están listos para su ejecución.
Dicha cola de ejecución de procesos se encuentra almacenada en la memoria
compartida. Cuando los procesos que se encuentran en la cola listos para su
ejecución son asignados a los procesadores de la siguiente manera: 1.-
Encuentra que el cache del procesador esta ocupad, por palabras de memoria
compartida que contiene al programa del proceso anterior. 2.- Después de un
pequeño intervalo de tiempo, se remplazara por el código y los datos del
programa del proceso que le ha sido asignado a dicho procesador.
5.7 Sistemas distribuidos como infraestructura
El modelo de sistema distribuido es el más general, por lo que, aunque no se ha
alcanzado a nivel comercial la misma integración para todo tipo de recursos, la
tendencia es clara a favor de este tipo de sistemas. La otra motivación es la
relación de costes a la que ha llevado la evolución tecnológica en los últimos
años. Hoy en día existe un hardware estándar de bajo coste, los ordenadores
personales, que son los componentes básicos del sistema. Por otra parte, la red
de comunicación, a no ser que se requieran grandes prestaciones, tampoco
constituye un gran problema económico, pudiéndose utilizar infraestructura
cableada ya existente (Ethernet, la red telefónica, o incluso la red eléctrica) o
inalámbrica.























{kind=link}